Robust measures of scale
In statistics, a robust measure of scale is a robust statistic that quantifies the statistical dispersion in a set of quantitative data. Robust measures of scale are used to complement or replace conventional estimates of scale such as the sample variance or sample standard deviation. As with other robust statistics, a robust measure of scale is minimally affected by a small fraction of outliers, at the cost of lower statistical efficiency when outliers are not present.
Contents |
IQR and MAD
The most familiar robust measures of scale are the interquartile range (IQR) and the median absolute deviation (MAD). The IQR is the difference between the 75th percentile and the 25th percentile of a sample. The interdecile range is a robust measure of scale that is closely related to the IQR. The MAD is the median of the absolute values of the differences between the data values and the overall median of the data set.
Robust measures of scale based on absolute pairwise differences
Rousseeuw and Croux[1] propose alternatives to the MAD, motivated by two weaknesses of it:
- It is inefficient (37% efficiency) at Gaussian distributions.
- it computes a symmetric statistic about a location estimate, thus not dealing with skewness.
They propose two alternative statistics based on pairwise differences: Sn and Qn, defined as:
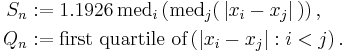
These can be computed in O(n log n) time and O(n) space.
Neither of these requires location estimation, as they are based only on differences between values. They are both more efficient than the MAD under a Gaussian distribution: Sn is 58% efficient, while Qn is 82% efficient.
For a sample from a normal distribution, Sn is approximately unbiased for the population standard deviation even down to very modest sample sizes (<1% bias for n = 10). For a large sample from a normal distribution, 2.219Qn is approximately unbiased for the population standard deviation. For small or moderate samples, the expected value of Qn under a normal distribution depends markedly on the sample size, so finite sample correction factors obtained from a table or from simulations are used to calibrate the scale of Qn.
The biweight midvariance
Like Sn and Qn, the biweight midvariance aims to be robust without sacrificing too much efficiency. It is defined as
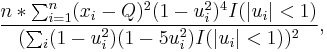
where I is the indicator function, Q is the sample median of the Xi, and
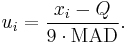
Its square root is a robust estimator of scale, since data points are downweighted as their distance from the median increases, with points more than 9 MAD units from the median having no influence at all.
The population analogue of a robust measure of scale
In some cases, robust estimators of scale are used to estimate the population variance or population standard deviation. For example, the IQR is sometimes defined as the difference between the 75th and 25th percentiles divided by 1.349, so that it becomes unbiased for the population variance if the data follow a normal distribution.
In other situations, it makes more sense to think of a robust measure of scale as an estimator of its own expected value, interpreted as an alternative to the population variance or standard deviation as a measure of scale. For example, the MAD of a sample from a standard Cauchy distribution is an estimator of the population MAD, which in this case is 1, whereas the population variance does not exist.
Simultaneous estimation of location and scale
Mizera & Müller (2004) propose a robust depth-based estimator for location and scale simultaneously.[2]
References
- ^ Rousseeuw, Peter J.; Croux, Christophe (December 1993), "Alternatives to the Median Absolute Deviation", Journal of the American Statistical Association (American Statistical Association) 88 (424): 1273–1283, doi:10.2307/2291267, JSTOR 2291267
- ^ Mizera, I.; Müller, C. H. (2004), "Location-scale depth", Journal of the American Statistical Association 99 (468): 949–966, doi:10.1198/016214504000001312.